全球科技业最大明星ChatGPT及背后的大模型混战,意外地让原本“需求下降”的芯片产业焕发新动力。
美股“七巨头”苹果、微软、谷歌、亚马逊、英伟达、脸书、特斯拉,全都是与芯片、AI相关的巨型科技公司,在过去一年股价市值飙升,全年涨幅最小的也达到50%,GPU霸主英伟达表现最为强劲,2023年市值增长239.2%,拉动纳斯达克指数全年上涨44.2%。在美联储大幅加息的背景下,被称为有史以来最奇怪的牛市。
这些高科技公司市值变化惊人,背后的关键逻辑是芯片业的技术进步,特别是GPU相关的技术革命。

黄仁勋在Computexu00a02023展会上发表演讲
过去一段时间,中国芯片业被美国针对,舆论更为关注手机SoC以及相关的制程工艺,比如7nm、5nm。华为麒麟9000S的问世,说明中国大陆突破了7nmu00a0SoC芯片的制造技术,形成了从设计、制造到商业的闭环。
不过,消费人群对GPU相关技术陌生,而恰恰在这方面中美相关产品在这方面的差距又非常明显。英伟达、AMD这些硅谷巨头还在不断加速提升先进GPU性能,中国自主产品性能差距被拉到十倍以上。
面对美国步步收紧的先进芯片出口管制,中国的人工智能产业,会因为算力和相关芯片性能有限被“卡脖子”而落后吗?我们可以从GPU技术的发展,英伟达这样的芯片“巨无霸”的成长历程,汲取到哪些可以借鉴的方法论?
英伟达的成功是靠运气吗?

第一款GPU:英伟达GeForceu00a0256
1999年英伟达发布GeForceu00a0256时正式提出Graphicsu00a0Processingu00a0Unit的概念,中文翻译过来即图形处理单元。
GPU的狭义概念即显卡——CPU无法处理屏幕上的图像,需要专门的显卡,早期有众多设计、生产显卡的公司。比如90年代颇有名气的3dfx,其1995年推出的3D加速卡Voodoo,让PC游戏性能大增。古墓丽影、雷神之锤等游戏让Voodoo名声大噪。1997年发布的Voodoo2在3D显卡技术竞争中更是独孤求败。时至今日,游戏玩家依旧是高端显卡的狂热用户群。
不过,Voodoo2并没有让3dfx一路领先。市面上的显卡产品种类繁多,游戏和3D应用的适配成为开发商最棘手的问题,微软适时推出了DirectX,统一规范硬件、软件厂商的设计,方便了开发。固执坚守自家生态的3dfx,面临被游戏、应用开发商孤立的局面。
与此同时,英伟达开始通过研发TNT系列产品来追赶3dfx,到第二代产品TNT2问世时已经完成对3dfx的性能超越,后者被动的卷入性能争夺战。英伟达推出革命性的GeForceu00a0256,在显卡芯片上实现了原来由CPU负责的TLTransformingu00a0u00a0Lighting,几何光影转换能力后,3dfx计划反击,但产品连续跳票,客户纷纷转投英伟达。
激烈的争夺战当中,微软成为压死3dfx的最后一根稻草。
面对英伟达的挑战,3dfx孤注一掷,决定用1.8亿美元收购图形芯片公司,争取微软Xbox游戏机图形芯片大单来挽救公司,但微软选择了英伟达。最终,陷入困境的3dfx被英伟达以7000万美元和100万股公司股票低价收购。
从1999年2月TNT2性能赶超,到1999年8月推出GeForceu00a0256,再到2000年底3dfx被收购,一家明星公司陨落之快,反映出了技术快速进步、尊重客户的重要性,也反映出了竞争的残酷性。
彼时,英伟达的胜利“基因”已经显现,但没人想象得到,这个“基因”价值如此巨大。在后来的GPU行业竞争中,广大客户的拥护、性能指标的快速迭代、各类应用算法的高效优化、稳定易用的软件引擎接口、大公司的支持、设计与制造分离,成为IT硬件公司持续竞争获胜的法宝。
PC高增长时代,英特尔、英伟达和AMD也是显卡领域的核心玩家。
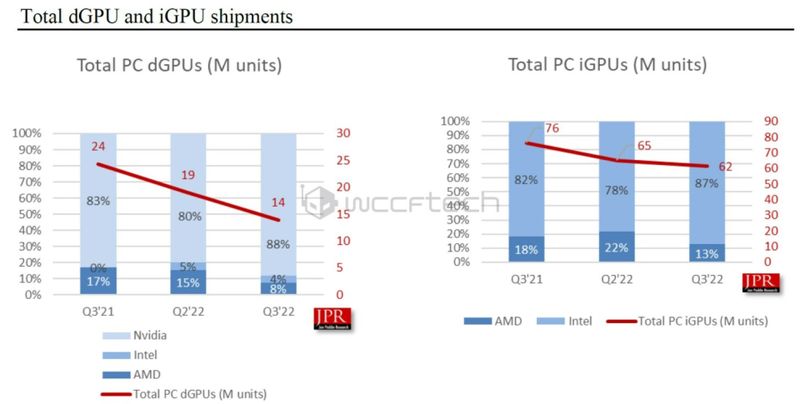
2021年Q3到2022年Q3,独立显卡与集成显卡市场份额占比,英伟达和英特尔分别占据绝对领先的份额
英特尔走的是集成显卡路线,直到2022年才推出独立显卡。AMD既有集成显卡,也发展独立显卡,2006年54亿美元收购了显卡公司ATI,走CPU和GPU“双路发展”的路线。在此之前的2004年,ATI开发的Radeonu00a09700显卡有1.1亿个晶体管,在技术上首次领先英伟达,和微软关系也更好,率先支持DirectXu00a09.0,获得了Xbox订单。英伟达则专注开发独立显卡,市场份额高达80%以上。
通用计算帮英伟达“开挂”
千禧年初期,一般用户有集成显卡就够了,独立显卡需求以游戏玩家为主,并非主流市场。而计算的逻辑,也以堆CPU的超算为代表,相比之下,GPU在计算方面的性能并不起眼。
2003年,GPU通用计算GPGPU概念被提出。之后多年英伟达几乎是凭“一己之力”,将GPU的通用计算功能发挥到了难以想象的高度。GPU跳出单一的3D图像显示应用场景,在随后的20年逐渐在神经网络、科学计算、云计算、AIGC、大语言模型等多个领域广泛应用。
通用计算成为英伟达增长的新引擎,游戏相关产品也发展很好,英伟达继续在游戏市场持续迭代GeForce系列产品,通过加入光线追踪等高级功能,性能一直领先。英伟达精准划分不同的SKU,适应需求差异化的用户群,此举也被称为创始人黄仁勋的“刀法”。
但真正让英伟达成为万亿美元市值传奇公司的,是2009年推出的用于数据中心的Tesla系列产品,如V100、A00、H100、H200,将GPGPU的高密度并行计算功能指标不断大幅提升。
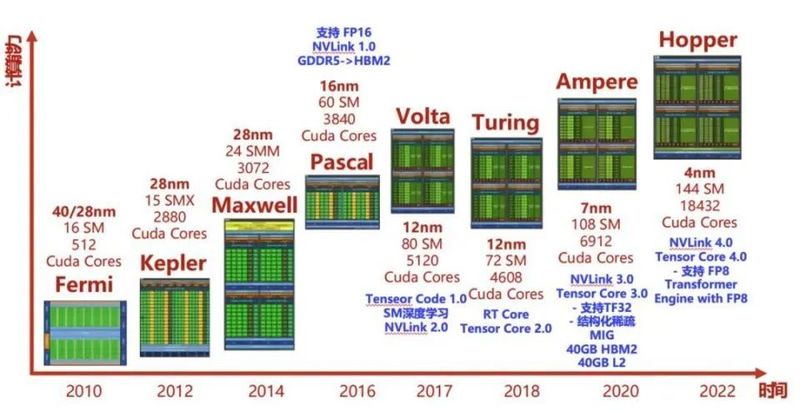
英伟达2010年开始推出的GPU架构及其对应的计算性能
英伟达“开挂”的黄金发展时间,至今大约是15年,其动力是GPU架构不断发展。这个过程中英伟达用科学家的名字对架构命名,以致敬科学先辈。H100和H200采用的Hopper架构,名称来自Graceu00a0Hopper格蕾丝·赫柏,计算机软件工程专家,bug这个词就是她在计算机继电器上找出一只小虫。
到目前为止,从英伟达的营收划分来看,“数据中心”业务的营收占比超过5成,成功超越“游戏娱乐”业务,后者只占3成多。另外还有不到10%聚焦“工业领域”,分别是主打高端图形,用于设计、建筑行业工业可视化的Quadro系列,以及主攻汽车自动驾驶领域的Orin系列。
总体来看,英伟达成为GPU霸主,主观原因在于不断的进行技术迭代,算法的优化、不断响应客户的差异化需求,以及大客户的支持等。
单纯以性能指标为例,以GPT-3应用评估算力,2023年的H100,在2021年的A100的基础上,性能翻了11倍,H200则翻了18倍,将推出的B100性能又是H200的两倍。期间尽管英伟达在“涨价”,但单位美元能完成的训练工作量也大幅提升。
客观上,英伟达的胜利和深度学习的流行关系很大,其针对人工智能应用深度优化的CUDAComputeu00a0Unifiedu00a0Deviceu00a0Architecture生态则是英伟达致胜的基石——它拥有上万名研发人员,开发者可直接使用CUDA开发库,不需要自行优化GPU相关代码,让英伟达拥有了用户惯性,软件、硬件两手都很硬。
可以说,在人工智能软件生态里,英伟达就相当于PC软件生态里的微软。
英伟达市值冲破万亿美元,还有一个罕见现象助推——时间优势——竞争对手就算能赶上英伟达,总要迟一些时间。
对于布局人工智能领域的巨头来说,时间是重要的考量因素之一,影响其布局的有几点:
一是英伟达竞争对手研发生产出对标产品要时间;
二是应用GPU的公司进行软硬件适配也要不短时间,而英伟达软件生态成熟能快速上手;
三是一些大型训练需要不短的时间,如果硬件性能与软件优化稍差一些,时间代价就会难以承受。
在ChatGPT爆火,AI硬件需求出乎预料地爆发增长的背景下,出现了“抢购”英伟达高性能GPU的现象。英伟达开出一块GPU几万美元的高价,各大公司豪气地以几万、十万计的数量“买卡”。
例如,印度数据中心运营商Yotta订购了16000个H100,到货期排到2024年7月了,近日又花5亿美元追订16000个H100和GH200,2025年3月前到货。社交媒体巨头Meta为了开发AGI通用人工智能,2024刚开年就抛出了35万块H100的订单炸场,加上已购的囤积60万块H100的超级算力。成本3000美元的H100卖3万美元,这一单的利润就超乎想象。
正是这些难以置信的超大订单,将英伟达股价顶上了600美元,市值突破1.5万亿美元。而市场需求的“好消息”似乎还没完,如AIu00a0PC又成为热门,人人都要高性能GPU让自己的PC变聪明。
GPU的超强算力来自哪里?
从现在眼光看,在架构上GPU的加速性能比CPU更出众,提升指标的办法更多,所以性能一直在快速进步。相比之下,CPU的计算速度提升已经放缓,更多是移动应用的功耗指标提升。一些指标进步还是靠与GPU集成实现的,比如苹果用于PC的M1、M2、M3系列芯片,集成显卡的性能飞速进步,M3跑出M1的图形性能只需一半功耗,峰值性能提升65%。
从硬件来看,GPU有两大类部件,一类是多个用于执行并行计算的计算单元,一类是存储数据的显存。
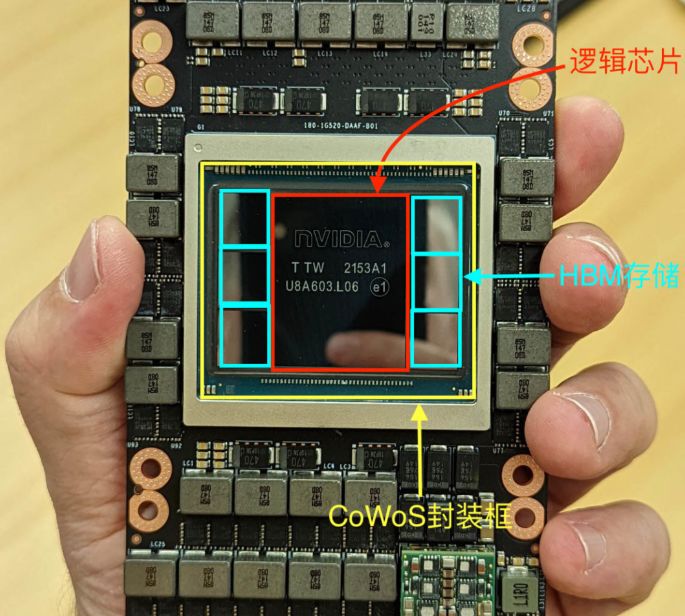
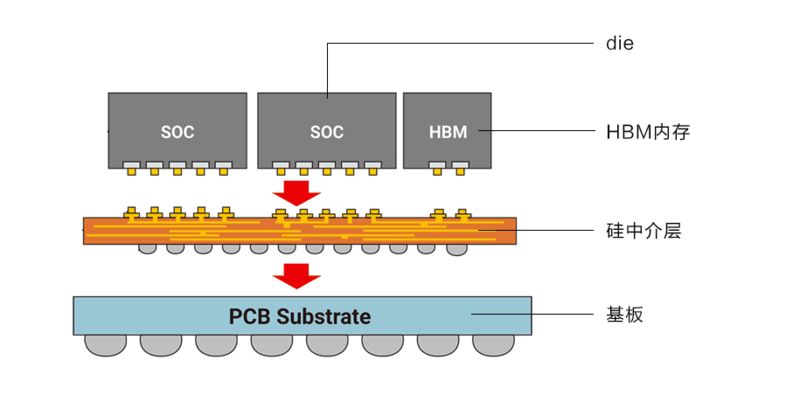
英伟达u00a0H100u00a0GPUu00a0SXM5模组,中间为1颗Hopperu00a0GPU逻辑计算芯片+6颗HDM内存
比如H100,有一颗英伟达设计的逻辑计算芯片,以及六颗各16GB的HBM3存储芯片如上图,采用台积电的CoWoSChipu00a0onu00a0Wafer,Waferu00a0onu00a0Substrate先进封装技术紧密连接组成一整块芯片。
通俗的理解,GPU的超级计算能力源于成千上万个计算单元,它的功能各异,要互相配合完成多种多样的图形处理、AI计算任务,且需要分级管理。相当于很多个CPU同时运行,尽管单个计算单元能力有限,叠加起来性能就会大幅跃升。不过,GPU的计算单元与CPU里的4核、8核多线程并行概念不同。
计算单元数量越来越多、功能越来越复杂高级,这正是英伟达从Fermi架构到Hopper架构不断优化的动力。
从计算意义上看,处于最顶层是整个GPU,它包含若干个次级的图形处理簇GPC,Graphicsu00a0Processingu00a0Cluster,某个图形处理簇处理完的数据,会通过Crossbar连接,分配给另外的图形处理簇继续处理。一个图形处理簇又包含数个流式多处理器SM,Streamu00a0Multiprocessor。
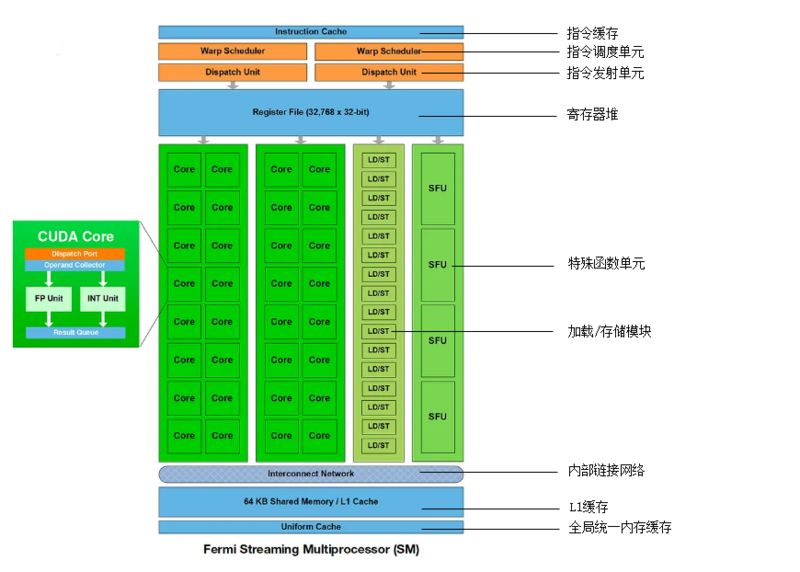
流式多处理器架构细节
以Fermi架构下单个流式多处理器为例,里面包含了多种部件,最显眼的是32个Core又叫做CUDAu00a0Core,如上图左边部分所示,也就是“流处理器”运算核心。Fermi架构的单个图形处理簇能高效完成一些指定的任务,成为一个引擎,如PolyMorphu00a0Engine多边形变形引擎,可以大幅度提升几何图形的处理能力。
*注:一般大型游戏的一帧画面包含数百万个几何多边形,CG动画中一帧画面中的多边形更是可以达到数亿个。

完整的英伟达Fermi架构示意图
如上图所示,完整的Fermi架构有4个图形处理簇、16个流式多处理器,总计512个CUDAu00a0Core。它们的特点是对向量进行处理,一个GPU时钟周期执行一次乘法、加法等操作,只要数据组织成向量就能加速。概括下来,CUDAu00a0Core的个数直接决定了GPU的常规处理能力。
随着深度学习兴起,矩阵和卷积运算在计算任务中的比例急剧上升。CUDAu00a0Core可以做矩阵和卷积,但单步能力有限,加速需要多个CUDAu00a0Core并行操作。从2017年的Volta架构开始,英伟达引入了Tensoru00a0Core来特别处理矩阵和卷积,效率进一步优化。在深度学习最常见的GEMM矩阵乘法中,Tensoru00a0Core一个时钟周期可以完成两个4*4*4的FP16浮点矩阵乘法,拼成一个FP32的矩阵结果,这提供了10多倍的效率加速。
总结下来,GPU的处理能力由CUDAu00a0Core和Tensoru00a0Core的数量所决定。公开资料显示,H100的SXM5版本有132组流式多处理器,有16896个FP32u00a0CUDAu00a0Core、528个Tensoru00a0Core。
*注:FP32、FP16代表单精度浮点数,可以用64bit、3bit、16bit、8bit来表示,分别称为FP64、FP32、FP16、FP8。位数少,运算部件的成本低、性能高,但是数据精度会下降。在AI应用中,对精度不太敏感,大量系数数值都是0,可以选用位数少的浮点数来加速,比如FP8。英伟达发布的Transformeru00a0Engine,利用FP8的加速特性,优化了Tensoru00a0Core算子,很好地支持了大模型训练。
除了大量的计算单元,影响GPU硬件性能的另一个重要指标是传输通道带宽。过去,数据主要通过PCIE数据通道在主机与GPU之间通信,如PCIEu00a03.0u00a0x16的带宽是16GB/S。使用GPU进行计算之后,显卡之间也要传输数据,英伟达开发了专门的NVLink传输通道连接显卡,带宽不断提升,H100的4代NVLink已经是900GB/S,是基于PCIE传输带宽的10倍以上。
以上关于计算单元,CUDAu00a0Core和Tensoru00a0Core数量以及传输带宽的案例,都是在强调,GPU强大的算力来源于诸多方面,在设计上可优化空间大,具体则包括显存大小、显存速度、缓存管理、数据通道、Core数量、单Core性能、数值精度、并行编程优化等等。
甚至在制造封装环节,比如纳米制程提升、先进封装工艺研发,对于英伟达自身和后来的追赶者,都有参与的空间,可以改进的环节远远超过CPU。目前,如CoWoS先进封装,要靠台积电的技术和产能。先进封装产能与订单数据,决定了高性能GPU出货量,非官方的数据显示,2024年台积电的CoWoS产能大概在每月2-3万片左右,而且产能还要分给苹果。
巨头自研GPU还有机会吗?
从绝对的水平来说,英伟达GPU技术并非遥不可及,作为对手的AMD就追的很激烈。
AMD推出的MI300,官方称部署GPT-4的性能超H100达到25%。对此,英伟达回应,应该以双方均优化之后的性能指标进行对比才算公平。在这方面,不少公司在规划自研或者已有针对特定任务进行优化的GPU产品。例如谷歌就自研了TPU,有能力给特定计算任务从设计到应用一条龙优化,定制适合的硬件。
近日,OpenAI也对外释放消息,称英伟达GPU成本太高,计划下场自研。
从技术角度,研发GPU是在大公司能力范围之内,美国IT大公司都有不错的芯片设计能力,七巨头都是芯片设计巨头,组织团队设计高性能GPU不是问题。
更多的问题来自成本——GPU设计与应用的环节非常复杂,如果把各环节都做好,优化空间极大,也可以获得更好的计算性能,但如果哪个环节做得不好,性能就会大打折扣,而性能非常关键,关乎的不仅仅是几块GPU,可能需要几万块、几十万块,数十亿美元的成本直接决定了能够下场自研的企业数量。
相比之下,英伟达的具备先发优势,整个应用生态和研发流程诸多环节都很顺畅,还在不断地提升性能。即便竞争对手在游戏渲染效果、大模型训练效率一路追赶,但也只是追平了上一代产品。如果GPU的性能还能继续高速提升,英伟达的霸主地位不会动摇,合理预期它会一直在市场技术指标、市场份额上大幅领先。
台积电CoWoSu00a02.5D封装示意图
另外,由于目前台积电的CoWoS等先进封装等制造技术还在进步,各种部件还没有像芯片纳米制程那样受到物理限制,GPU架构还能不断升级,流式多处理器与Core的数量还能不断增加。
英伟达的优势明显,但并不代表对手没有机会,核心的问题在于产能——抢购英伟达GPU都要排到一年以后才到货,有足够GPU技术能力的公司也会有市场,比如AMD就是替代选项之一,而硅谷的科技巨头在供应链的建设上,也习惯培养后备力量避免被单一合作伙伴“卡脖子”。
相比之下,中国市场的情况较为特殊,由于受到出口管制的影响,有大量潜在的空白市场待填补。据了解,一些公司目前也在借助大模型训练,进行国产GPU的适配,半年左右的开发,可以实现A100芯片60%-70%的性能。
与此同时,大公司在相关出口管制条例出来之前,已经有大量相关算力的储备,在这种情况下,培育国产GPU生态更加任重道远。
从整个芯片设计市场来说,CPU也在进步,尤其是通过先进封装集成GPU,比如苹果的M系列芯片、高通的Snapdragonu00a0Xu00a0Elite,这说明高性能芯片的潜力还很大。只是从大众需求的角度看,PC、手机的CPU芯片性能已经存在过剩,没有太多市场想象力,而相反,就与AI的大规模应用,GPU大众应用的想象力是开放的。比如在围棋AI领域,GPU算力高,围棋AI的水平就高,GPU性能成了围棋AI弱机、强机的判定者。
可以想象,自己的AI助手有多聪明,很可能是配备的GPU性能决定的,那GPU的市场前景还望不到尽头。
本文来源:腾讯科技
